Fiction Tagging Engine: Manually Processing Tags
Tag Data Exploration

Clustering the tags together gave me a deep dive into the themes, fandoms, and fandom genres of the data I collected. From this exploration I discovered I will eventually need to build in some kind of hierarchy so that a tag about sisters, also pulls in the sibling, family, and relationship tag groups. Right now the dataset doesn’t have such a hierarchy, but I believe it will be useful for an algorithm learning how to tag fiction to have that type of relationship documented in the dataset eventually.
Manually processing the tags is tedious but worthwhile since a human will know the ‘happy childhood’ and ‘childhood abuse’ belong in separate categorizations even though they share a common word, but a machine is not likely to understand that. I am hoping to fine tune already trained models, however I also weary of doing that because bias (towards marginalized groups like disabled people; queer people; Black, Asian, Indigenous, and Latinx people; trans people; etc.) can be so ingrained the data being used that people don’t see they’re creating a biased algorithm.
The manual process consisted of opening up each CSV file and going through each list, putting tags into related group(s). I did this for the fandom tags, genre tags, and the additional tags. A friend pointed out that I should also do the relationship (e.g. Cressida & Johanna Mason*, Cressida/Johanna Mason*, etc.) and relationship category (e.g. F/F, M/M, F/M, etc.) since this will also show if a story has platonic or romantic relationships and what kind of relationships they are (hetero, same sex, polyamorous etc.).
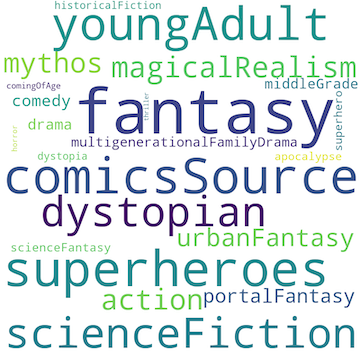
Data Visualizations
Word clouds made from the first dataset with two of the engineered feature columns.

* In fanfic relationships, a / typically means a romantic and/or sexual relationship whereas a & means a platonic relationship (typically a friendship, not a QPR from what I can tell).